Anyone with hands-on experience setting up long-haul VPNs over the Internet knows it’s not a pleasant exercise. Even factoring out the complexity of appliances and the need to work with old relics like IPSEC, managing latency, packet loss and high availability remain huge problems. Service providers also know this -- and make billions on MPLS.
The bad news is that it is not getting any better. It doesn’t matter that available capacity has increased dramatically. The problem is in the way providers are interconnected and with how global routes are mismanaged. It lies at the core of how the Internet was built, its protocols, and how service providers implemented their routing layer. The same architecture that allowed the Internet to cost-effectively scale to billions of devices also set its limits.
Addressing these challenges requires a deep restructuring in the fabric of the Internet and core routing - and should form the foundation for possible solutions. There isn’t going to be a shiny new router that would magically solve it all.
IP Routing’s Historical Baggage: Simplistic Data Plane
Whether the traffic is voice, video, HTTP, or email, the Internet is made of IP packets. If they are lost along the way, it is the responsibility of higher-level protocols such as TCP to recover them. Packets hop from router to router, only aware of their next hop and their ultimate destination.
Routers are the ones making the decisions about the packets, according to their routing tables. When a router receives a packet, it performs a calculation according to its routing table - identifying the best next hop to send the packet to.
From the early days of the Internet, routers were shaped by technical constraints. There was a shortage of processing power available to move packets along their path, or data plane. Access speeds and available memory were limited, so routers had to rely on custom hardware that performed minimal processing per packet and had no state management. Communicating with this restricted data plane was simple and infrequent.
Routing decisions were moved out to a separate process, the control plane, which pushed its decisions, finding the next router on the way to the destination, back into the data plane.
This separation of control and data planes allowed architects to build massively scalable routers, handling millions of packets per second. However, even as processing power increased on the data plane, it wasn't really used. The control plane makes all the decisions, the data plane executes the routing table, and apart from routing table updates, they hardly communicate.
A modern router does not have any idea how long it actually took a packet to reach its next hop, or whether it reached it at all. The router doesn’t know if it’s congested. And to the extent it does have information to share, it will not be communicated back to the control plane, where routing decisions are actually made.
BGP - The Routing Decisions Protocol
BGP is the routing protocol that glues the Internet together. In very simple terms, its task is to communicate the knowledge of where an IP address (or a whole IP subnet) originates. BGP involves routers connecting with their peers, and exchanging information about which IP subnets they originate, and also “gossip” about IP subnets they learned about from other peers. As these rumors propagate between the peers and across the globe, they are appended with the accumulated rumor path from the originator (this is called the AS-Path). As more routers are added to the path, the “distance” grows.
Here is an example of what a router knows about a specific subnet, using Hurricane Electric’s excellent looking glass service. It learned about this subnet from multiple peers, and selected the shortest AS-Path. This subnet originates from autonomous system 13150, the rumor having reached the router across system 5580. Now the router can update its routing table accordingly.
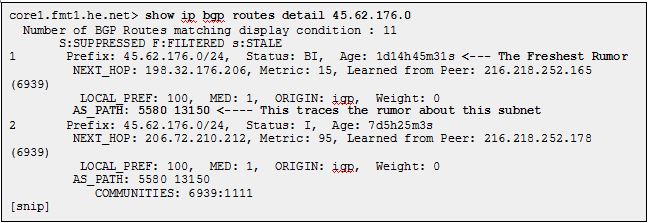
If we want to see how traffic destined for this IP range is actually routed, we can use traceroute. Note that in this case, there was a correlation between the AS-Path, and the path the actual packets traveled.
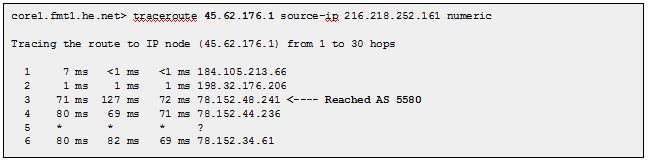

BGP is a very elegant protocol, and we can see why it was able to scale with the Internet: it requires very little coordination across network elements. Assuming the routers performing the protocols are the ones that are actually routing traffic, it has a built in resiliency. When a router fails, so will the routes it propagated, and other routers will be selected.
BGP has a straightforward way of assessing distance: it uses the AS-Path, so if it got the route first-hand it is assumed to be closest. Rumored routes are considered further away as the hearsay “distance” increases. The general assumption is that the router that reported the closest rumor is also the best choice send packets. BGP doesn’t know if a specific path has 0% or 20% packet loss. Also, using the AS-Path as a method to select smallest latency is pretty limited: it’s like calculating the shortest path between two points on the map by counting traffic lights, instead of miles, along the way.
A straightforward route between Hurricane Electric (HE), a tier-1 service provider, as seen from Singapore, to an IP address in China, has a path length of 1.
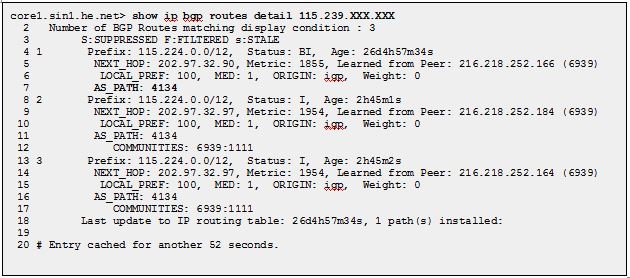
But if we trace the path the packets actually take from Singapore to China, the story is really different: packets seem to make a “connection” in Los Angeles.

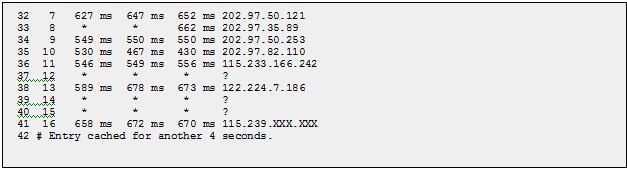
This packet traveled to the West coast of the U.S. to get from Singapore to China simply because HE peers with China Telecom in Los Angeles. Every packet from anywhere within the HE autonomous system will go through Los Angeles to reach China Telecom.
BGP Abused: BGP Meets the Commercial Internet
To work around BGP’s algorithms, the protocol itself extends to include a host of manual controls to allow manipulation of the “next best hop” decisions. Controls such as weight, local preference (prioritizing routes from specific peers), communities (allow peers to add custom attributes, which may then affect the decisions of other peers along the path), and AS path prepending (manipulates the propagated AS path) allow network engineers to tweak and improve problematic routes and to alleviate congestion issues.
The relationship between BGP peers on the Internet is a reflection of commercial contracts of ISPs. Customers pay for Internet traffic. Smaller service providers pay larger providers, and most pay tier-1 providers. Any non-commercial relationship has to be mutually beneficial, or very limited.
BGP gives service providers the tools to implement these financial agreements:
-Service providers usually prefer routing traffic for “paying” connections.
-Service providers want to quickly get rid of “unpaid” packets, rather than carrying them across their backbone (so called “hot potato” routing).
-Sometimes, service providers will carry the packets over long distances just to get the most financially beneficial path.
All this comes at the expense of best path selection.
The MPLS Racket
To address these problems, service providers came up with an alternative offering: private networks, built on their own backbones, using MPLS as the routing protocol.
MPLS is in many ways the opposite of BGP. Instead of an open architecture, MPLS uses policy based, end-to-end routing. A packet's path through the network is predetermined, which makes it suitable only for private networks. This is why MPLS is sold by a single provider, even if the provider patched together multiple networks behind the scenes to reach customer premises.
MPLS is a control plane protocol. It has many of the same limitations as BGP: routing is decided by policy, not real traffic conditions, such as latency or packet loss. Providers are careful about bandwidth management to maintain their SLAs.
The combination of single vendor lock-in and the need for planning and overprovisioning to maintain SLAs make these private networks a premium, expensive product. As the rest of the Internet, with its open architecture, became increasingly competitive and cost-efficient, MPLS faces pressure. As a backbone implementation, it is not likely to ever become affordable.
A Way Forward
The Internet just works. Not flawlessly, not optimally, but packets generally reach their destination. The basic structure of the Internet has not changed much over the past few decades, and has proven itself probably beyond the wildest expectations of its designers.
However, it has key limitations:
- The data plane is clueless. Routers, which form the data plane, are built for traffic load, and are therefore stateless, and have no notion of individual packet or traffic flows.
- Control plane intelligence is limited. Because the control plane and the data plane are not communicating, the routing decisions are not aware of packet loss, latency, congestion, or actual best routes.
- Shortest path selection is abused: Service providers’ commercial relationships often work against the end user interest in best path selection.
The limited exchange between the control and data planes has been taken to the extreme in OpenFlow and Software-defined Networking (SDN): the separation of the control plane and data plane into two different machines. This might be a good solution for cutting costs in the data center, but to improve global routing, it makes more sense to substantially increase information sharing between the control plane and the data plane.
To solve the limitations of the Internet it’s time to converge the data and control planes to work closely together, so they are both aware of actual traffic metrics, and dynamically selecting the best path.
About the Author

Gur Shatz is co-founder and CTO of Cato Networks, a Network Security as a Service provider based in Tel Aviv. Prior to Cato Networks, he was the co-founder and CEO of Incapsula Inc., a cloud-based web applications security and acceletration company. Before Incaspula, Gur was director of Product Development, vice president of Engineering and vice president of Products at Imperva, a web application security and data security company.
Edited by
Peter Bernstein